Identificación del idioma en una red neuronal profunda
Translation into Spanish of an interesting article by Conor O’Sullivan, an Irish data scientist who likes to write about Interpretable ML, explainable AI, algorithm fairness and data exploration.
 28 April, 2022 Neural network language identification
28 April, 2022 Neural network language identificationA free translation by Chema, a Spain-based translator specializing in English to Spanish translations
An original text written by Conor O’Sullivan, originally published in
https://towardsdatascience.com/deep-neural-network-language-identification-ae1c158f6a7d
* * *
Cómo clasificar el idioma de un texto usando DNN y n-gramas de caracteres (con código Python)
La identificación del idioma puede ser un paso importante dentro de un proyecto de Procesamiento del Lenguaje Natural (NLP por sus siglas en Inglés). Se trata de intentar detectar el idioma de un fragmento de texto. Es importante conocer el idioma de un texto antes de poder realizar otras acciones (traducción, análisis de opiniones, etc). Por ejemplo, si vas a Google Translate, e introduces un texto a traducir, verás que indica ‘Detectar idioma’. Esto es porque Google está tratando de identificar el idioma de la frase que estás escribiendo, antes de que intentar traducirla.
Existen varios enfoques diferentes para la identificación de idioma. En este artículo exploraremos uno de ellos: el uso de una red neuronal y n-gramas de caracteres. Demostraremos que con este enfoque se puede lograr una precisión de más del 98%. Por el camino, analizaremos fragmentos clave de código. Puedes encontrar el proyecto completo en GitHub. Antes de nada, explicaremos el set de datos que usaremos para entrenar nuestra red neuronal.
Set de datos
Usaremos un set de datos de Tatoeba. El set de datos completo consta de 6.872.356 oraciones en 328 idiomas únicos. Para simplificar nuestro problema usaremos:
- 6 idiomas latinos: inglés, alemán, español, francés, portugués e italiano.
- Frases de entre 20 y 200 caracteres.
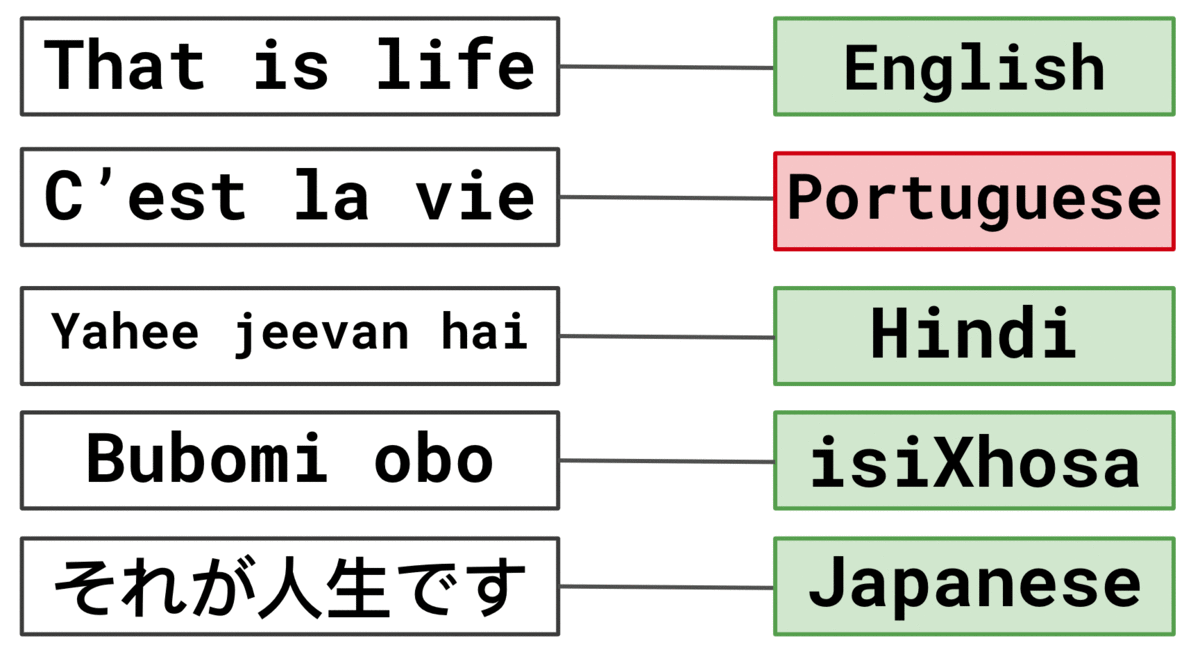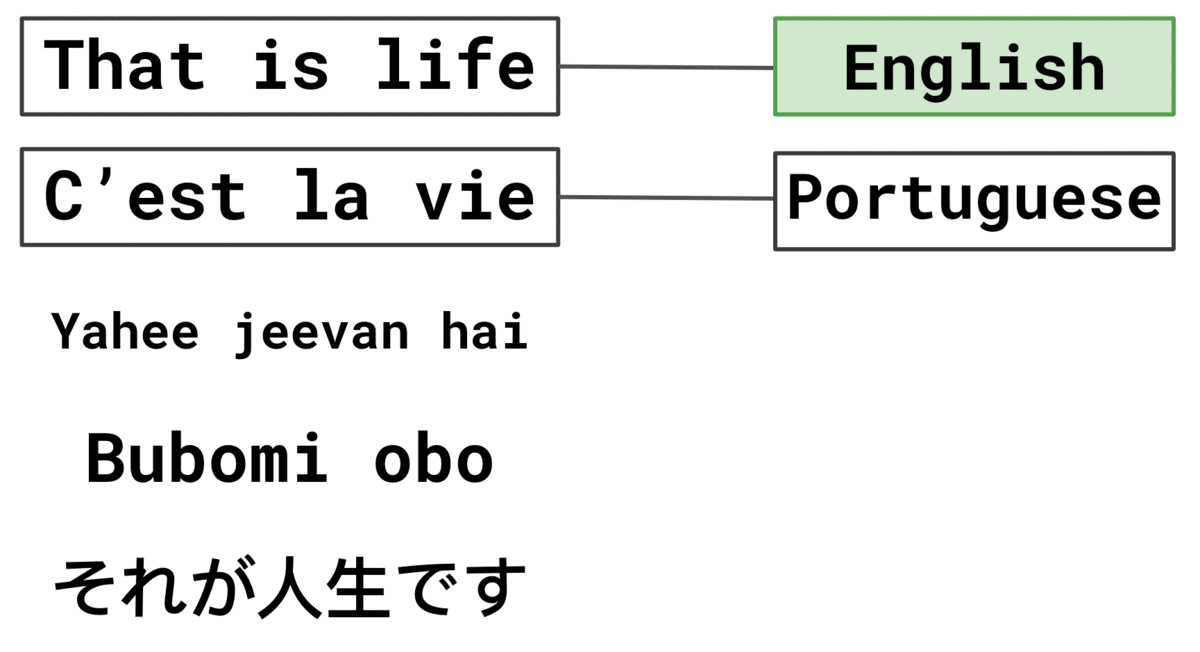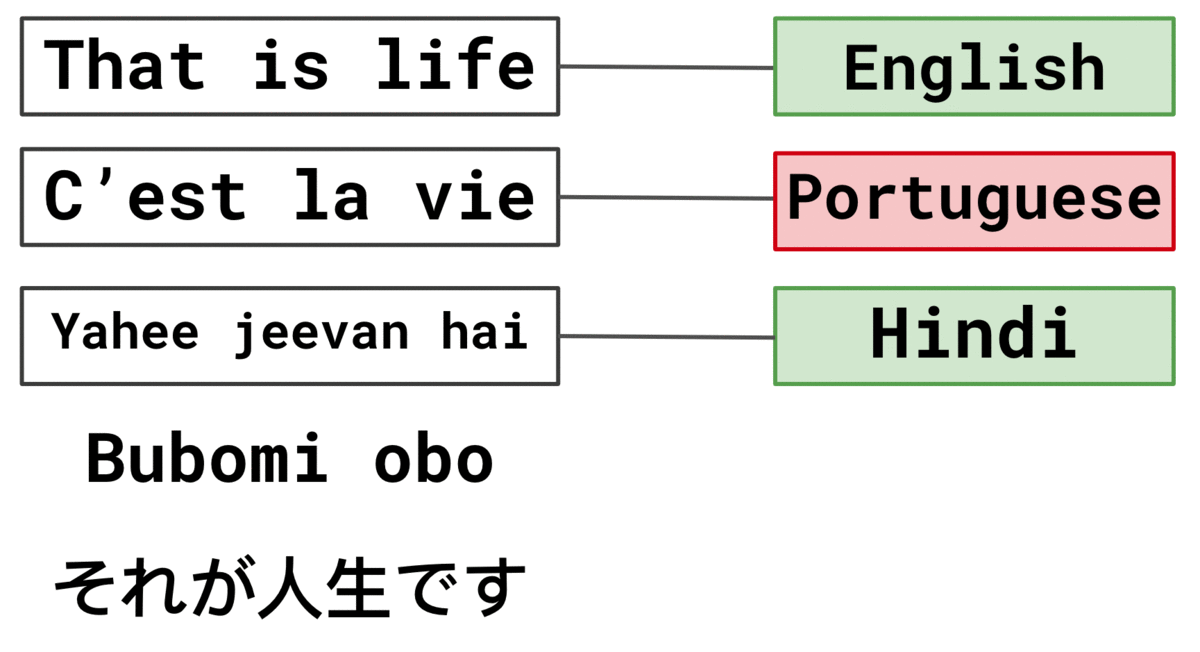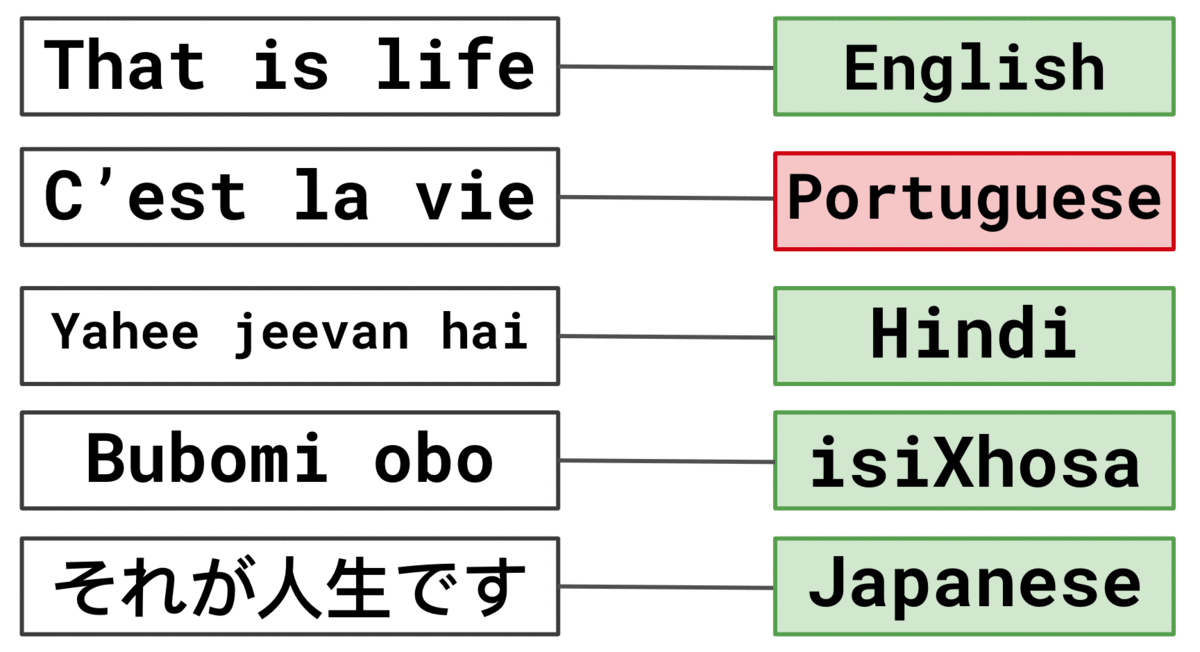
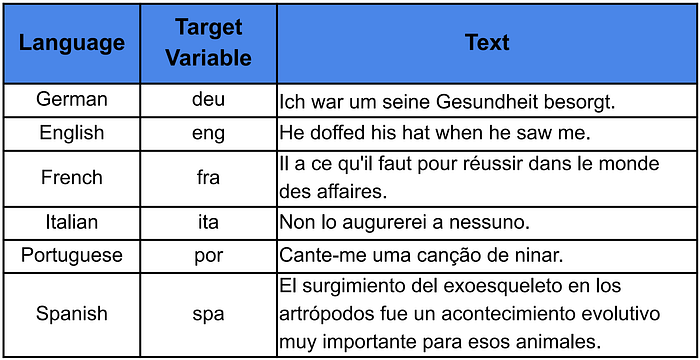
Podemos ver un ejemplo de una oración de cada idioma en la Tabla 1. Nuestro objetivo es crear un modelo que pueda predecir la Variable objetivo utilizando el Texto proporcionado.
Cargamos el conjunto de datos y comenzamos a trabajar. Primero filtramos el conjunto de datos para obtener oraciones de la longitud y el idioma deseados. Seleccionamos al azar 50.000 oraciones de cada uno de estos idiomas para tener 300.000 filas en total. Estas oraciones luego se dividen en un conjunto de entrenamiento (70%), validación (20%) y prueba (10%).
import pandas as pd
Read in full dataset
data = pd.read_csv('../data/sentences.csv',
sep='\t',
encoding='utf8',
index_col=0,
names=['lang','text'])
Filter by text length
len_cond = [True if 20<=len(s)<=200 else False for s in data['text']]
data = data[len_cond]
Filter by text language
lang = ['deu', 'eng', 'fra', 'ita', 'por', 'spa']
data = data[data['lang'].isin(lang)]
Select 50000 rows for each language
data_trim = pd.DataFrame(columns=['lang','text'])
for l in lang:
lang_trim = data[data['lang'] ==l].sample(50000,random_state = 100)
data_trim = data_trim.append(lang_trim)
Create a random train, valid, test split
data_shuffle = data_trim.sample(frac=1)
train = data_shuffle[0:210000]
valid = data_shuffle[210000:270000]
test = data_shuffle[270000:300000]
Matriz de características
Antes de poder ajustar un modelo, tenemos que transformar nuestro conjunto de datos en algo comprensible para una red neuronal. En otras palabras, necesitamos extraer características de nuestra lista de oraciones para crear una matriz de características. Hacemos esto usando n-gramas de caracteres que son conjuntos de n caracteres consecutivos. Este es un enfoque similar a un modelo de bolsa de palabras , excepto que estamos usando caracteres y no palabras.
Para nuestro problema de identificación de idiomas, usaremos caracteres de 3 gramos/trigramas (es decir, conjuntos de 3 caracteres consecutivos). En la Figura 2, vemos un ejemplo de cómo se pueden vectorizar oraciones usando trigramas. En primer lugar, obtenemos todos los trigramas de las oraciones. Para reducir el espacio de características, tomamos un subconjunto de estos trigramas. Usamos este subconjunto para vectorizar las oraciones. El vector para la primera oración es [2,0,1,0,0] ya que el trigrama ‘is_’ aparece dos veces y ‘his’ aparece una vez en la oración.

El proceso para crear nuestra matriz de características de trigramas es similar pero un poco más complicado. En la siguiente sección, profundizaremos en el código utilizado para crear la matriz. Antes de eso, vale la pena tener una descripción general de cómo creamos nuestra matriz de características. Los pasos tomados son:
- Usando el conjunto de entrenamiento, seleccionamos los 200 trigramas más comunes de cada idioma
- Crea una lista de trigramas únicos a partir de estos trigramas. Los idiomas comparten algunos trigramas comunes, por lo que terminamos con 663 trigramas únicos.
- Cree una matriz de características, contando la cantidad de veces que aparece cada trigrama en cada oración
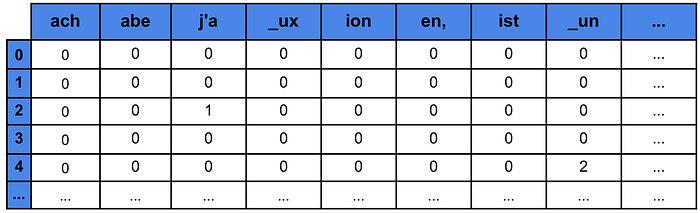
Podemos ver un ejemplo de una matriz de características de este tipo en la Tabla 2. La fila superior muestra cada uno de los 663 trigramas. Luego, cada una de las filas numeradas da una de las oraciones en nuestro conjunto de datos. Los números dentro de la matriz dan la cantidad de veces que ocurre ese trigrama dentro de la oración. Por ejemplo, “j’a” aparece una vez en la oración 2.
Creando las características
En esta sección, repasamos el código utilizado para crear la matriz de características de entrenamiento en la Tabla 2 y la matriz de características de validación/prueba. Hacemos un uso extensivo del paquete CountVectorizer proporcionado por SciKit Learn. Este paquete nos permite vectorizar texto basado en alguna lista de vocabulario (es decir, una lista de palabras/caracteres). En nuestro caso, la lista de vocabulario es un conjunto de 663 trigramas.
En primer lugar, tenemos que crear esta lista de vocabulario. Empezamos por obtener los 200 trigramas más comunes de cada idioma. Esto se hace usando la función get_trigrams en el siguiente código. Esta función toma una lista de oraciones y devolverá la lista de los 200 trigramas más comunes de estas oraciones.
from sklearn.feature_extraction.text import CountVectorizer
def get_trigrams(corpus,n_feat=200):
"""
Returns a list of the N most common character trigrams from a list of sentences
params
------------
corpus: list of strings
n_feat: integer
"""
#fit the n-gram model
vectorizer = CountVectorizer(analyzer='char',
ngram_range=(3, 3)
,max_features=n_feat)
X = vectorizer.fit_transform(corpus)
#Get model feature names
feature_names = vectorizer.get_feature_names()
return feature_names
En el código a continuación, recorremos cada uno de los 6 idiomas. Para cada idioma, obtenemos las oraciones relevantes del conjunto de entrenamiento. Luego usamos la función get_trigrams para obtener los 200 trigramas más comunes y agregarlos a un conjunto. Al final, como los idiomas comparten algunos trigramas comunes, tenemos un conjunto de 663 trigramas únicos. Los usamos para crear una lista de vocabulario.
#obtain trigrams from each language
features = {}
features_set = set()
for l in lang:
#get corpus filtered by language
corpus = train[train.lang==l]['text']
#get 200 most frequent trigrams
trigrams = get_trigrams(corpus)
#add to dict and set
features[l] = trigrams
features_set.update(trigrams)
#create vocabulary list using feature set
vocab = dict()
for i,f in enumerate(features_set):
vocab[f]=i
Luego, el paquete CountVectorisor utiliza la lista de vocabulario para vectorizar cada una de las oraciones en nuestro conjunto de entrenamiento. El resultado es la matriz de características de la Tabla 2 que vimos anteriormente.
#train count vectoriser using vocabulary
vectorizer = CountVectorizer(analyzer='char',
ngram_range=(3, 3),
vocabulary=vocab)
#create feature matrix for training set
corpus = train['text']
X = vectorizer.fit_transform(corpus)
feature_names = vectorizer.get_feature_names()
train_feat = pd.DataFrame(data=X.toarray(),columns=feature_names)
El paso final, antes de que podamos entrenar nuestro modelo, es escalar nuestra matriz de características. Esto ayudará a nuestra red neuronal a converger a los pesos de parámetros óptimos. En el código a continuación, escalamos la matriz de entrenamiento usando una escala mínima-máxima.
#Scale feature matrix
train_min = train_feat.min()
train_max = train_feat.max()
train_feat = (train_feat - train_min)/(train_max-train_min)
#Add target variable
train_feat['lang'] = list(train['lang'])
También necesitamos obtener las matrices de características para los conjuntos de datos de validación y prueba. En el siguiente código, vectorizamos y escalamos los 2 conjuntos como hicimos con el conjunto de entrenamiento. Es importante notar que usamos la lista de vocabulario así como los valores mínimos/máximos obtenidos del conjunto de entrenamiento. Esto es para evitar cualquier fuga de datos.
create feature matrix for validation set
corpus = valid['text']
X = vectorizer.fit_transform(corpus)
valid_feat = pd.DataFrame(data=X.toarray(),columns=feature_names)
valid_feat = (valid_feat - train_min)/(train_max-train_min)
valid_feat['lang'] = list(valid['lang'])
create feature matrix for test set
corpus = test['text']
X = vectorizer.fit_transform(corpus)
test_feat = pd.DataFrame(data=X.toarray(),columns=feature_names)
test_feat = (test_feat - train_min)/(train_max-train_min)
test_feat['lang'] = list(test['lang'])
Explorando los trigramas
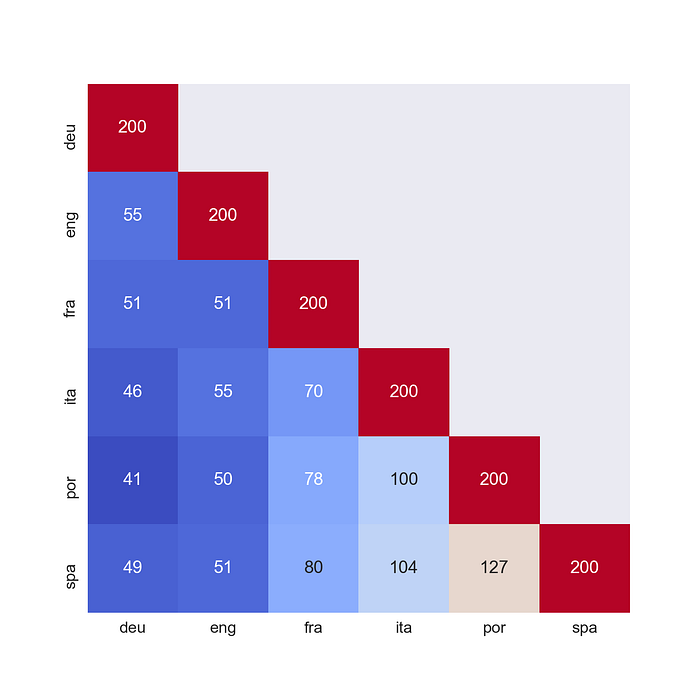
Ahora tenemos los conjuntos de datos en un formulario listo para usar para entrenar nuestra red neuronal. Antes de hacer eso, sería útil explorar el conjunto de datos y desarrollar un poco de intuición sobre qué tan bien funcionarán estas funciones para predecir los idiomas. La Figura 2 da el número de trigramas que cada idioma tiene en común con los demás. Por ejemplo, el inglés y el alemán tienen en común 55 de sus trigramas más comunes.
Con 127, vemos que el español y el portugués tienen la mayor cantidad de trigramas en común. Esto tiene sentido ya que, entre todos los idiomas, estos dos son los más similares léxicamente. Lo que esto significa es que, utilizando estas características, nuestro modelo puede tener dificultades para distinguir el español del portugués y viceversa. De manera similar, el portugués y el alemán tienen menos trigramas en común y podríamos esperar que nuestro modelo sea mejor para distinguir estos idiomas.
Modelado
Usamos el paquete keras para entrenar nuestro DNN. Se utiliza una función de activación softmax en la capa de salida del modelo. Esto significa que tenemos que transformar nuestra lista de variables de destino en una lista de codificaciones one-hot. Esto se hace usando la función de codificación a continuación. Esta función toma una lista de variables objetivo y devuelve una lista de vectores codificados one-hot. Por ejemplo, [eng,por,por, fra,…] se convertiría en [[0,1,0,0,0,0],[0,0,0,0,1,0],[0,0, 0,0,1,0],[0,0,1,0,0,0],…].
from sklearn.preprocessing import LabelEncoder
from keras.utils import np_utils
Fit encoder
encoder = LabelEncoder()
encoder.fit(['deu', 'eng', 'fra', 'ita', 'por', 'spa'])
def encode(y):
"""
Returns a list of one hot encodings
Params
---------
y: list of language labels
"""
y_encoded = encoder.transform(y)
y_dummy = np_utils.to_categorical(y_encoded)
return y_dummy
Antes de elegir la estructura del modelo final, realicé algunos ajustes de hiperparámetros. Varié la cantidad de nodos en las capas ocultas, la cantidad de épocas y el tamaño del lote. La combinación de hiperparámetros que logró la mayor precisión en el conjunto de validación se eligió para el modelo final.
El modelo final tiene 3 capas ocultas con 500, 500 y 250 nodos respectivamente. La capa de salida tiene 6 nodos, uno para cada idioma. Todas las capas ocultas tienen funciones de activación de ReLU y, como se mencionó, la capa de salida tiene una función de activación de softmax. Entrenamos este modelo usando 4 épocas y un tamaño de lote de 100. Usando nuestro conjunto de entrenamiento y la lista de variables de destino codificadas en caliente, entrenamos este DDN en el código a continuación. Al final, conseguimos una precisión de entrenamiento del 99,70 %.
from keras.models import Sequential
from keras.layers import Dense
#Get training data
x = train_feat.drop('lang',axis=1)
y = encode(train_feat['lang'])
#Define model
model = Sequential()
model.add(Dense(500, input_dim=663, activation='relu'))
model.add(Dense(500, activation='relu'))
model.add(Dense(250, activation='relu'))
model.add(Dense(6, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#Train model
model.fit(x, y, epochs=4, batch_size=100)
Evaluación del modelo
Durante el proceso de entrenamiento del modelo, el modelo puede verse sesgado hacia el conjunto de entrenamiento y el conjunto de validación. Por lo tanto, es mejor determinar la precisión del modelo en un conjunto de prueba invisible. La precisión final en el conjunto de prueba fue del 98,26 %. Esto es inferior a la precisión de entrenamiento del 99,70 %, lo que sugiere que se ha producido un sobreajuste en el conjunto de entrenamiento.
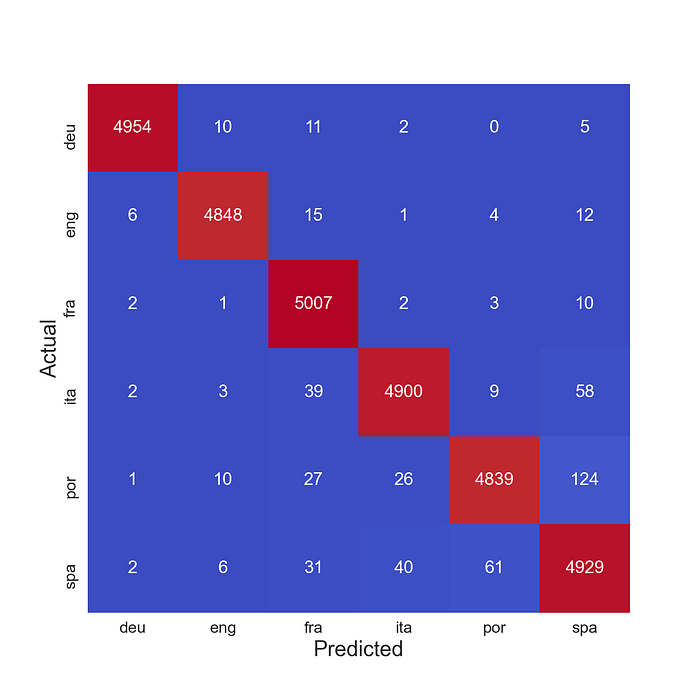
Podemos tener una mejor idea de qué tan bien funciona el modelo para cada idioma mirando la matriz de confusión en la Figura 3. La diagonal roja da el número de predicciones correctas para cada idioma. Los números fuera de la diagonal dan la cantidad de veces que un idioma se predijo incorrectamente como otro. Por ejemplo, el alemán se predice incorrectamente como inglés 10 veces. Vemos que el modelo confunde con mayor frecuencia portugués con español (124 veces) o español con portugués (61 veces). Esto se deduce de lo que vimos al explorar nuestras características.
El código utilizado para crear esta matriz de confusión se proporciona a continuación. En primer lugar, usamos nuestro modelo entrenado anteriormente para hacer predicciones en el conjunto de prueba. Usando estos idiomas predichos y los idiomas reales, creamos una matriz de confusión y la visualizamos usando un mapa de calor marino.
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import accuracy_score,confusion_matrix
x_test = test_feat.drop('lang',axis=1)
y_test = test_feat['lang']
#Get predictions on test set
labels = model.predict_classes(x_test)
predictions = encoder.inverse_transform(labels)
#Accuracy on test set
accuracy = accuracy_score(y_test,predictions)
print(accuracy)
#Create confusion matrix
lang = ['deu', 'eng', 'fra', 'ita', 'por', 'spa']
conf_matrix = confusion_matrix(y_test,predictions)
conf_matrix_df = pd.DataFrame(conf_matrix,columns=lang,index=lang)
#Plot confusion matrix heatmap
plt.figure(figsize=(10, 10), facecolor='w', edgecolor='k')
sns.set(font_scale=1.5)
sns.heatmap(conf_matrix_df,cmap='coolwarm',annot=True,fmt='.5g',cbar=False)
plt.xlabel('Predicted',fontsize=22)
plt.ylabel('Actual',fontsize=22)
Al final, la precisión de la prueba del 98,26 % deja margen de mejora. En cuanto a la selección de características, hemos simplificado las cosas y hemos seleccionado los 200 trigramas más comunes para cada idioma. Un enfoque más complicado podría ayudarnos a diferenciar los idiomas que son más similares. Por ejemplo, podríamos seleccionar trigramas que son comunes en español pero no tanto en portugués y viceversa. También podríamos experimentar con diferentes modelos. Con suerte, este es un buen punto de partida para sus experimentos de identificación de idiomas.
Fuentes de imagen
Todas las imágenes son mías u obtenidas de www.flaticon.com. En este último, tengo una “licencia completa” tal y como se define en su Plan Premium.
Referencias
[1] A. Simões, JJ Almeida y SD Byers. Language identification: a neural network approach. (2014) https://www.researchgate.net/publication/290102620_Language_identification._A_neural_network_approach
[2] GR Botha y E. Barnard. Factors that affect the accuracy of text-based language identification (2012) https://www.sciencedirect.com/science/article/abs/pii/S0885230812000058