Traducción automática simple: del yorùbá a inglés
Translation into Spanish of an interesting article by Abid Ali Awan, a certified data scientist professional, master in technology management with a degree in telecommunications engineering, who loves building machine learning models.
 10 June, 2022 Yoruba-English machine translation template.
10 June, 2022 Yoruba-English machine translation template.A free translation by Chema, a Spain-based translator specializing in English to Spanish translations, with a growing interest in Machine Learning Models and Machine Translation.
An original text written by Abid Ali Awan, originally published in
https://towardsdatascience.com/simple-machine-translation-yor%C3%B9b%C3%A1-to-english-1b958ccdc8a1
* * *
Cómo ajustar el modelo multilenguaje PNL de Helsinki para traducir del yorùbá al inglés.

Introducción
En este artículo construiremos un modelo de traducción automática para traducir oraciones del yorùbá al inglés. Estas oraciones son de varios tipos, como artículos de noticias, conversaciones en las redes sociales, transcripciones orales y libros escritos exclusivamente en yorùbá.
La traducción automática para idiomas de pocos recursos no es habitual, y es bastante difícil obtener resultados precisos cuando no hay mucha cantidad de datos disponibles en estos idiomas. Tenemos una base de datos para el texto yoruba (JW300), pero que relacionado con el ámbito de las religiones. Necesitamos un modelo generalizado que pueda luego utilizarse en múltiples ámbitos: en ai4d.ai vamos a poder encontrar muchos más datos y lo único que habrá que hacer es alimentar nuestro modelo con estos datos para que de un buen resultado y asegurar el primer puesto en el Desafío de traducción automática de yorùbá AI4D — Zindi .
En este proyecto usaremos el modo Helsinki NLP, así que hablemos de ellos como organización.
Helsinki PNL
El Grupo de Investigación de Tecnología del Lenguaje de la Universidad de Helsinki alimentó modelos de PNL (Programación Neurolinguística) de Helsinki. Su objetivo es poder dar una traducción automática para todos los idiomas que existen. También estudian los mecanismos de procesamiento del lenguaje humano, que incluyen revisión automática de ortografía y gramática, traducción automática y ASR (Automatic Speech Recognition o reconocimiento automático del habla). Para obtener más información, visite Tecnología del lenguaje. Estos modelos están disponibles públicamente en HuggingFace y en GitHub.
Importación de memorias esenciales
Selección de opciones
- Para que el texto se vea limpio, tienes que hacer que la opción Limpiar aparezca comoTrue, para poder ir ampliando la base de datos sin tener que ir borrando cosas.
- Si quieres alimentar el modelo, tienes que hacer que Train aparezca también como True .
Lectura de los datos del modelo
Puedes ir leyendo los datos de alimentación mediante pandas para tener un conocimiento inicial de cómo se ve nuestra base de datos.
Los datos de alimentación consisten en 10.054 oraciones paralelas en la combinación Yorùbá-inglés. Tenemos tres columnas: ID (identificadores únicos), yoruba (contiene texto en yorùbá) y English (traducción del texto del inglés al yorùbá). Los datos se ven bastante limpios y no faltan valores.
Limpieza de datos
Eliminamos los signos de puntuación, ponemos el texto a un nivel más bajo y eliminamos los dígitos del texto para que nuestro modelo funcione mejor. Por ahora, mantendremos esta función desactivada, pero la usaremos más adelante para futuros experimentos.
El tokenizador y el modelo
Hemos utilizado joyas escondidas de traducción automática que se hicieron en varios idiomas, incluido el yorùbá. Los modelos de PNL de Helsinki son unos de los mejores en la traducción automática y vienen con la opción de poder transferirlos, por lo que podremos usar el mismo modelo con el mismo tamaño y ajustarlo a nuestra nueva base de datos para obtener todavía mejores resultados. Usaremos el modelo Helsinki-NLP/opus-mt-mul-en · Hugging Face y lo ajustaremos a un texto yorùbá más generalizado proporcionado por Artificial Intelligence for Development-Africa Network (ai4d.ai).
El modelo está disponible públicamente en Hugging face y es bastante fácil de descargar y alimentar usando la biblioteca de transformadores. Usaremos GPU y añadiremos.to(cuda)para activar la GPU en este modelo.
- grupo de origen : varios idiomas
- grupo objetivo : Inglés
- readme de OPUS : mul-eng
- modelo : transformador
Si tienes una buena conexión a Internet, no te llevará mucho descargar y cargar el modelo.
Downloading: 100% 1,15k/1,15k [00:00<00:00, 23,2kB/s]
Downloading: 100% 707k/707k [00:00<00:00, 1,03MB/s]
Downloading: 100% 791k/ 791k [00:00<00:00, 1,05 MB/s]
Downloading: 100 % 1,42 M/1,42 M [00:00<00:00, 2,00 MB/s]
Downloading : 100 % 44,0/44,0 [00:00< 00:00, 1.56kB/s]
Downloading : 100% 310M/310M [00:27<00:00, 12.8MB/s]
Preparación del modelo para la alimentación
Optimizador
Usaremos el optimizador AdamW para hacer que nuestro modelo converja rápidamente y dé mejores resultados con una tasa de aprendizaje de 0,0001. He trabajado con diferentes optimizadores disponibles en la biblioteca PyTorch y AdamW es el que mejor funciona para este problema. Al ajustar los hiperparámetros, obtuve un muy buen resultado con una tasa de aprendizaje de 0,0001.
He utilizado la técnica de ekshusingh para afinar el modelo de PNL de Helsinki. Es rápido de entrenar y requiere pocas muestras para producir mejores resultados.
He realizado algunos ajustes de hiperparámetros y obtenido parámetros finales de 27 Epochs y 32 tamaños de lote.
La función model_train()primero divide el lote en local_Xy local_y. Vamos a usar la función prepare_seq2seq_batchdel tokenizador para convertir el texto en tokens, que se pueden usar como entrada para nuestro modelo. Luego usaremos la opción de descenso de gradiente para optimizar las pérdidas e imprimir la pérdida final.
Alimentación
La alimentación de un modelo ha durado 30 minutos con 27 Epochs y cada Epoch ha tardado aproximadamente 38 segundos en ejecutarse. La pérdida final ha sido de 0,0755, que es bastante buena y, por lo tanto, es evidente que nuestro modelo ha funcionado bien, pero aún tenemos que comprobarlo en la métrica de evaluación.
100% 125/125 [00:38<00:00, 3,84 it/s]
Loss: tensor (0.0755, device='cuda: 0', grad_fn = <DivBackward0>)
Modelo de prueba
Se prueba en una sola muestra del conjunto de datos de prueba.
El modelo ha funcionado bastante bien y la frase ahora tiene sentido. Habrá que eliminar los corchetes y los <pad> de otros signos de puntuación innecesarios para dejar nuestra base de datos limpia.
Usando una cadena suby replace hemos podido eliminar<pad>,', [,]de nuestro texto.
El texto final se ve limpio y es casi perfecto para una evaluación inicial.
Predicciones a partir de la base de datos de prueba
Vamos a predecir a partir de la base de datos de prueba y verificar si nuestro modelo ha funcionado bien. Para ello, subimos la base de datos de prueba a la plataforma Zindi.
Se genera una predicción y se decodifica el tensor en texto por lotes. Mediante.progress_apply, hemos traducido todo el texto en yoruba de la base de datos de prueba y lo hemos movido a una nueva columna llamadaLabel
La traducción predicha queda limpia:
A continuación nos encontramos con la versión final del conjunto de datos de prueba, que es bastante precisa. Para verificar cómo se ha desarrollado nuestro modelo en la base de datos de prueba, probamos a subir el archivo en la plataforma Zindi.
Métrica
La competencia utiliza la métrica Rouge Score y cuanto mayor sea la puntuación, mejor funcionará el modelo. La puntuación de nuestro modelo en la tabla de clasificación es de 0,3025, que no está mal, lo que te llevará al top 20.
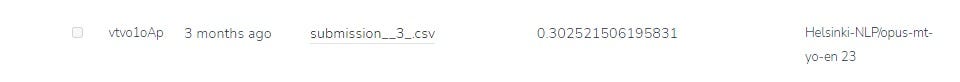
Conclusión
Utilizando el poder del aprendizaje por transferencia, hemos creado un modelo que ha funcionado bastante bien con un texto en yoruba estándar. El modelo multilenguaje de traducción automática de PNL de Helsinki funcionó bien. He experimentado con muchos modelos disponibles públicamente en HugginFace y opus-mt-mul-en, que funcionan mejor en lenguajes con pocos recursos. Debido al traductor de Google, la investigación de traducción automática se ha visto afectada de forma negativa, pero este traductor no ofrece servicio de traducción para idiomas con pocos recursos, y estos idiomas suelen ser menos precisos, por lo que aplicarle tu modelo de traducción automática te va a dar la libertad de traducir cualquier idioma de pocos recursos con el uso de transformadores. Al final, esto fue con lo que empecé, y tras varios experimentos y preprocesando el texto, obtuve el puesto 14º en la competición, con una puntuación final de 0,35168.
Puedes encontrar mi modelo en kingabzpro/Helsinki-NLP-opus-yor-mul-en · Hugging Face