Últimos avances en Procesamiento del Lenguaje Natural (PLN)
Translation into Spanish of an interesting article by Aman Anand Rai, a Data Science & Machine Learning enthusiast living in Ballia, India. Aman loves to write about Machine Learning, NLP, Language Modeling, Machine Translation, Deep Learning, PHP, Python, etc.
 27 April, 2022 Advances in the field of NLP
27 April, 2022 Advances in the field of NLPA free MT translation by DeepL postedited by Chema, a Spain-based translation student specializing in English to Spanish translations
An original text written by Aman Anand Rai, originally published in
https://dev.to/amananandrai/recent-advances-in-the-field-of-nlp-33o1
* * *
El Procesamiento del Lenguaje Natural, comúnmente llamado PLN (o NLP en sus siglas en Inglés) por los expertos en aprendizaje automático, es un campo que está evolucionando rápidamente. Con la llegada de los bots de IA como Siri, Cortana, Alexa y el Asistente de Google, el uso del PNL se ha incrementado enormemente. Los últimos esfuerzos se centran en construir modelos que puedan comprender mejor idiomas como el inglés, el español, el chino mandarín, el hindi, el japonés, etc., los conocidos formalmente como Lenguajes Naturales.
Los usos más comunes del Procesamiento del Lenguaje Natural en nuestra vida diaria son los motores de búsqueda, la traducción automática, los chatbots y los asistentes domésticos.
Comencemos definiendo los dos términos “Lenguaje Natural” y “Procesamiento del Lenguaje Natural” de una manera mucho más formal.
Lenguaje natural
Se entiende como “lenguaje natural” todo lenguaje que se ha desarrollado de forma natural entre los seres humanos.
Procesamiento natural del lenguaje
El Procesamiento del Lenguaje Natural (NLP) es la capacidad de un programa de ordenador para comprender los lenguajes humanos, tal y como se hablan. El objetivo final de la PNL es leer, descifrar, comprender y dar sentido a los lenguajes humanos de una manera útil.
La PNL tiene dos áreas especialmente importantes:
1. Comprensión del lenguaje natural
2. Generación del lenguaje natural
Comprensión del lenguaje natural
La comprensión del lenguaje natural busca crear un modelo de aprendizaje automático o aprendizaje profundo que pueda comprender el lenguaje hablado por los humanos. En otras palabras, un sistema capaz de comprender el discurso oral o escrito. Se podría usar para resolver muchos problemas del mundo real: preguntas y respuestas, resolución de consultas, análisis de sentimientos, detección de similitudes en textos, chatbots, etc. Si un sistema es capaz de entender el lenguaje natural, podría, él solo, responder a nuestras respuestas.
Generación de lenguaje natural
La generación de lenguaje natural es la capacidad de un modelo de aprendizaje automático para generar resultados en forma de texto o audio en lenguaje comprensible por un ser humano. En esta tarea, generamos oraciones a partir de conjuntos de datos de texto predefinidos utilizando el modelo. Se utiliza para resumir texto, responder consultas o preguntas, traducción automática (traducción de un idioma a otro) y generación de respuestas.
En los últimos dos o tres años se han hecho muchos avances en el campo de la PNL. Esto ha sido posible debido al aumento de recursos en forma de grandes conjuntos de datos de texto, plataformas en la nube para el entrenamiento de grandes modelos y la necesidad de los humanos de comunicarse con los ordenadores en un lenguaje comprensible para ambos. Pero el factor más importante es el descubrimiento de los transformers y su arquitectura y el uso de Transfer Learning en el campo de la PNL.
Ahora, los modelos se entrenan previamente en grandes conjuntos de datos y luego este modelo preentrenado con sus parámetros o pesos ajustados se usa para resolver la tarea requerida. Este proceso de usar modelos previamente entrenados para resolver problemas reales se conoce como transferencia de aprendizaje . El modelo preentrenado está ajustado para realizar tareas como clasificación de texto, etiquetado de partes del discurso, reconocimiento de entidades nombradas, resumen de texto y respuesta a preguntas, etc. Algunos de los términos pueden ser bastante desconocidos para las personas que son nuevas en el campo del aprendizaje automático o la PNL, así que no dude en preguntar sobre ellos en la sección de comentarios o simplemente búsquelos en Google para una mejor comprensión y profundización en el campo de la PNL.
A continuación se detallan algunos de los avances recientes en el campo del procesamiento del lenguaje natural.
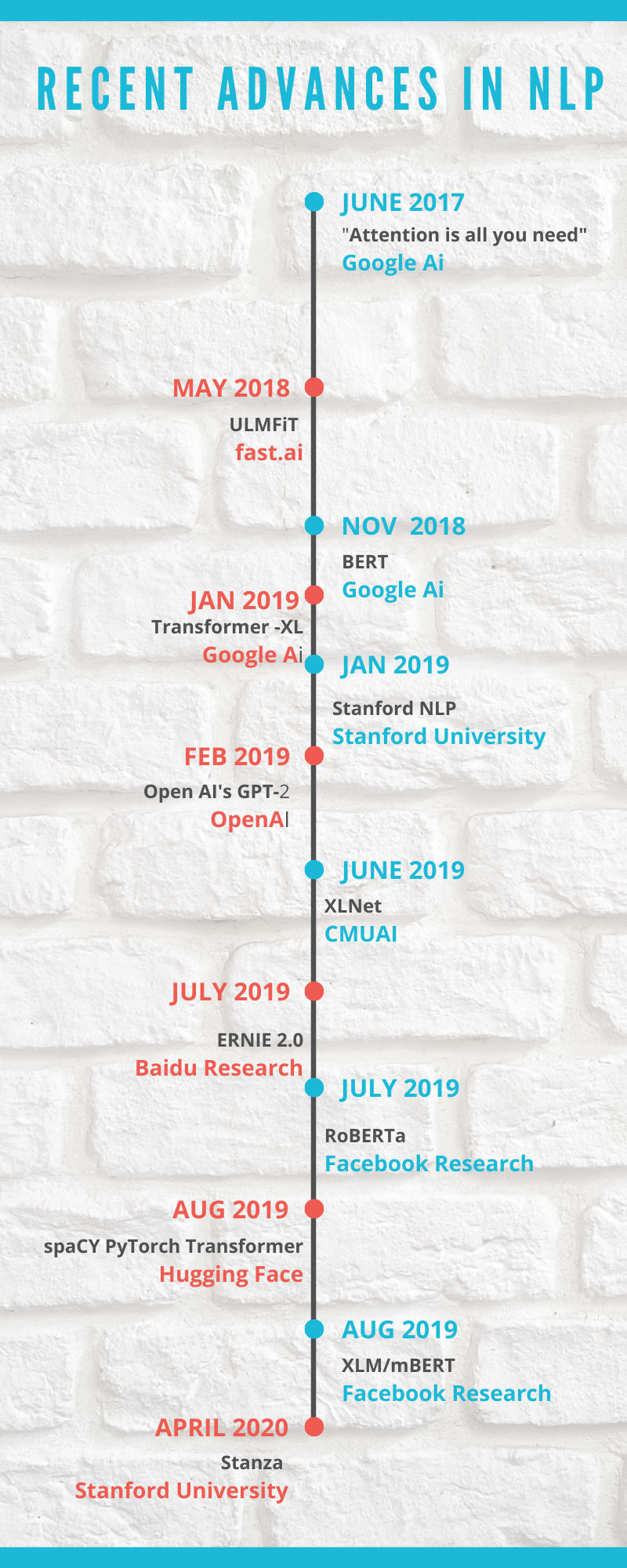
1. La atención es todo lo que se necesita
– IA de Google. Junio de 2017
“Attention is all you need” (en Español “La atención es todo lo que se necesita”) fue un artículo de investigación publicado por los empleados de Google. Ashish Vaswani et. Alabama publicaron este artículo que revolucionó la industria de la PNL. Fue la primera vez que se hizo referencia al concepto de transformers. Antes de este artículo, se usaban RNN y CNN en el campo de la PNL, pero tenían dos problemas:
- Lidiar con dependencias a largo plazo
- Sin paralelización durante el entrenamiento
Los RNN no pudieron lidiar con las dependencias a largo plazo, incluso con diferentes mejoras, como RNN bidireccionales o LSTM y GRU. Los transformers con auto-atención ayudaron a resolver estos problemas e hicieron un gran avance en la PNL. Era lo último en modelos seq2seq aplicados a la traducción de idiomas.
2. ULMFiT (Ajuste fino del modelo de lenguaje universal)
– fast.ai. Mayo de 2018
El otro desarrollo más importante fue el uso del aprendizaje por transferencia en el campo de la PNL. Este modelo de lenguaje introdujo el concepto de transferencia de aprendizaje a la comunidad de PNL. Es un único modelo de lenguaje universal ajustado para múltiples tareas. El mismo modelo se puede ajustar para resolver 3 tareas diferentes de PNL. AWD-LSTM forma el bloque de construcción de este modelo. AWD son las siglas en inglés de “Asynchronous Stochastic Gradient Descent Weight Dropped”.
3. BERT (Representación de codificador bidireccional de transformers)
– IA de Google. Noviembre de 2018
Utiliza el concepto de los dos avances mencionados anteriormente, es decir, Transformers y transferencia de aprendizaje. Realiza un entrenamiento bidireccional completo de transformes. Es el modelo más avanzado para hasta 11 tareas de PNL. Está previamente entrenado con todo el conjunto de datos de Wikipedia en Inglés (casi 2.500 millones de palabras).
4. Transformer-XL de Google
– IA de Google. Enero de 2019
Este modelo superó incluso a BERT en modelado de lenguaje. También resolvió el problema de la fragmentación del contexto al que se enfrentaban los Transformers originales.
5. Stanford PNL
– Universidad de Stanford. Enero de 2019
El sitio oficial lo define como:
StanfordNLP es un paquete de análisis de lenguaje natural de Python. Contiene herramientas que se pueden usar en una canalización, para convertir una cadena que contiene texto en lenguaje humano en listas de oraciones y palabras, para generar formas base de esas palabras, sus partes del discurso y características morfológicas, y para dar una dependencia de estructura sintáctica así como para analizar gramaticalmente.
Contiene modelos neuronales preentrenados para 53 idiomas humanos. Por lo tanto, aumenta el alcance de la PNL a un nivel global en lugar de limitarse solo al inglés.
6. GPT de OpenAI -2
– OpenAI. Febrero de 2019
GPT-2 significa “Transformer preentrenado generativo 2”, como su nombre indica, se usa básicamente para tareas relacionadas con la parte de generación de lenguaje natural de NLP. Este es el modelo más avanzado para la generación de texto . GPT-2 tiene la capacidad de generar un artículo completo basado en pequeñas oraciones de entrada. También se basa en transformadores. GPT-2 logra puntuaciones de vanguardia en gran variedad de tareas de modelado de lenguaje específicas. No se entrena en ninguno de los datos específicos de ninguna de estas tareas y solo se evalúa en ellos como prueba final; esto se conoce como configuración de “disparo cero”.
7. XLNet
– CMU IA. Junio de 2019
Utiliza métodos autorregresivos para el modelado del lenguaje en lugar de la codificación automática utilizada en BERT. Utiliza las mejores características de BERT y TransformerXL.
8. Transformers PyTorch
– Hugging face. Julio 2019
La empresa Hugging Face ha desarrollado una maravillosa herramienta, llamada PyTorch Transformers, con la que podemos usar BERT, XLNET y TransformerXL como modelos SOTA con unas pocas líneas de código Python.
9. Representación mejorada de Baidu a través de la integración del conocimiento. ERNIE de Baidu – Investigación de Baidu. Julio de 2019
El gigante de búsqueda chino Baidu creó este modelo con una función de entrenamiento previo continuo. Es un modelo de comprensión del idioma preentrenado que logró los resultados más avanzados (SOTA) y superó a BERT y al reciente XLNet en 16 tareas de PNL tanto en chino como en inglés.
10. RoBERTa: un enfoque de preentrenamiento BERT sólidamente optimizado
– Investigación de Facebook. Julio de 2019
Es la mejora de Facebook AI sobre BERT. El equipo de desarrollo de Facebook AI optimizó el proceso de capacitación y los hiperparámetros de BERT para lograr este modelo.
11. spaCy-PyTorch – Transformers
– spaCy + Hugging face. Agosto de 2019
Es un Transformer PyTorch para procesamiento de lenguaje. También se utiliza para el despliegue de Transformers. spaCy se usa junto con PyTorch para construir los Transformers.
12. XLM/mBERT de Facebook AI
– Investigación de Facebook. Agosto de 2019
Modelo lingüístico multilingüe compuesto por casi 100 idiomas. Es lo más avanzado para clasificación multilingüe y la traducción automática.
13. Stanza
– Universidad de Stanford. Abril de 2020
Es la versión avanzada de StanfordNLP y admite 66 idiomas. Stanza presenta una canalización totalmente neuronal independiente del idioma para el análisis de texto que incluye; tokenización, expansión de token de varias palabras, lematización, etiquetado de características morfológicas y de parte del discurso, análisis de dependencia y reconocimiento de entidades nombradas.
Lecturas adicionales para una mejor comprensión de los temas mencionados anteriormente:
- 1. https://arxiv.org/abs/1706.03762
- 2. https://arxiv.org/abs/1810.0480
- 3. http://jalammar.github.io/illustrated-bert/
- 4. https://openai.com/blog/better-language-models/
- 5. https://arxiv.org/abs/1907.11692
- 6. http://research.baidu.com/Blog/index-view?id=121
- 7. https://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/
- 8. https://arxiv.org/abs/1901.02860