SwinIR, la IA que multiplica por 8 la nitidez de fotografías faciales borrosas
Translation into Spanish of an interesting article by Louis Bouchard, AI advocate, writter, and speaker. Co-founder & Head of Community at Towards AI, Louis focuses on making AI accessible, sharing and explaining artificial intelligence terms and news the best way possible in order to demystify the AI “black box” and sensitize people about the risks of using it.
aiimage upscalingspanish translationswinai
11 June, 2022Photos enhanced with AI technology
11 June, 2022Photos enhanced with AI technology
A Spanish translation reviewed & postedited by Inés, a Spain-based translation student specializing in English to Spanish translations
¡Convierte tus imágenes de 512 px a 4K gracias a la Inteligencia Artificial!
Ver vídeo
¿Alguna vez te ha pasado que había una foto que te gustaba mucho, pero de la que sólo tenías una versión minúscula, como la de esta imagen de arriba a la izquierda? ¿No sería genial poder coger esa imagen y hacer que se viera el doble de bien? Suena bien, pero ¿qué pasaría si pudieras mejorarla 4 o incluso 8 veces más? Eso sí que sería genial. Pues hoy vamos a ver cómo mejorar la resolución de una imagen un 400%, logrando cuatro veces más píxeles de alto y ancho, más detalles, y mayor nitidez. Lo mejor es que esto se consigue en unos pocos segundos, de forma completamente automática, y funciona con prácticamente cualquier imagen. Ah, y puedes hacerlo tú mismo con una versión de demo que han puesto a disposición de todo el mundo, como veremos en el video.
Aumento del número de píxeles de una imagen (image upsampling)
Antes de profundizar en este increíble modelo, tenemos que explicar el concepto de sobremuestreo de fotos o superresolución de imagen. El objetivo aquí es construir una imagen de alta resolución a partir de una imagen de baja resolución, que en este caso es una cara, pero podría ser cualquier objeto, animal o paisaje. La imagen de baja resolución tendrá 512 píxeles o menos; no será muy borrosa, pero claramente quedará lejos de una imagen en alta definición, sobre todo si la ponemos a pantalla completa.
Ejemplo de imagen de baja definición.
Mírala en detalle. Cogemos esta imagen de baja definición y la transformamos en una imagen de alta definición. mucho más nítida. En este caso, una imagen de 2048 píxeles cuadrados, que es cuatro veces más HD.
Imagen mejorada usando SwinIR.
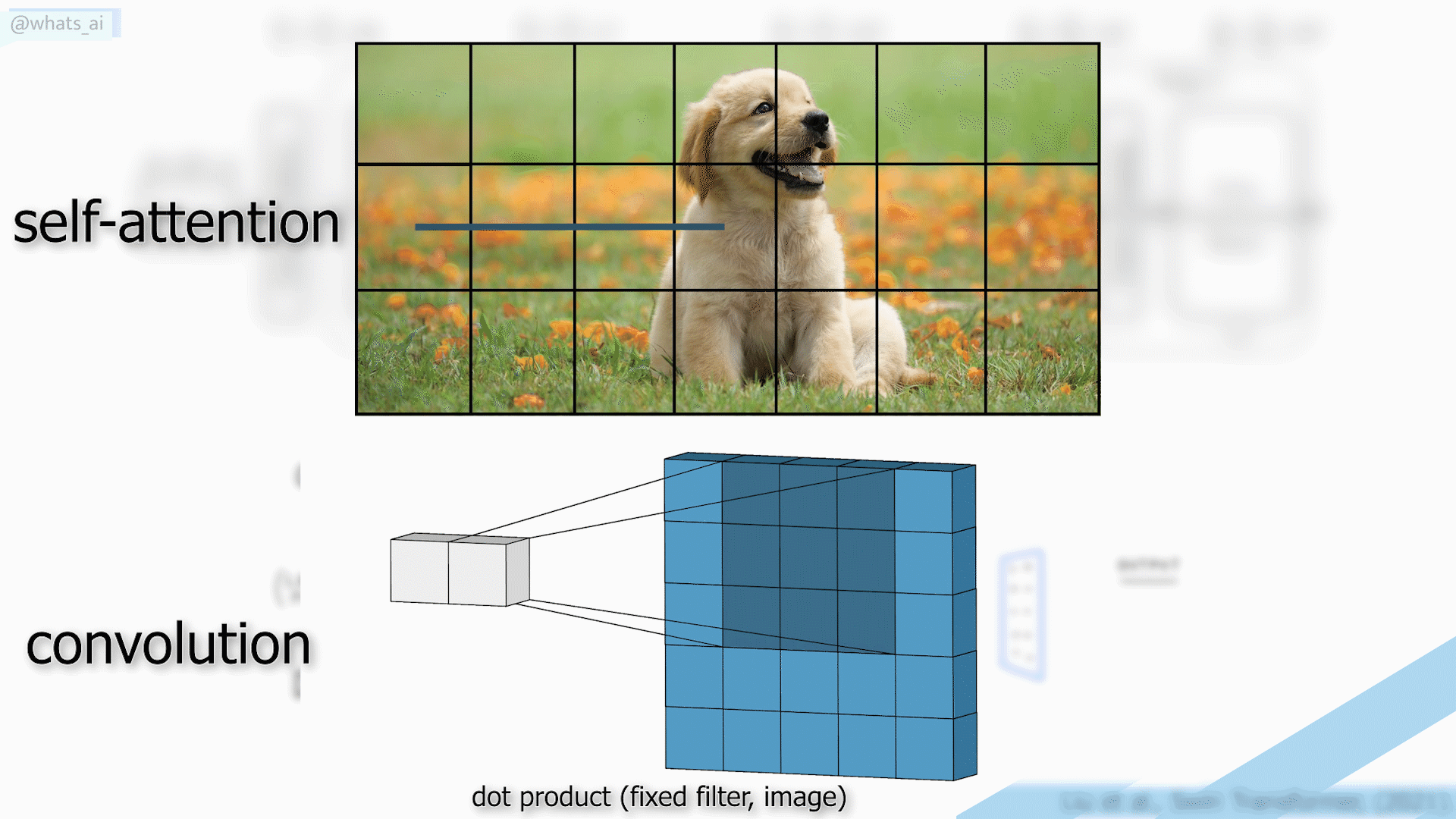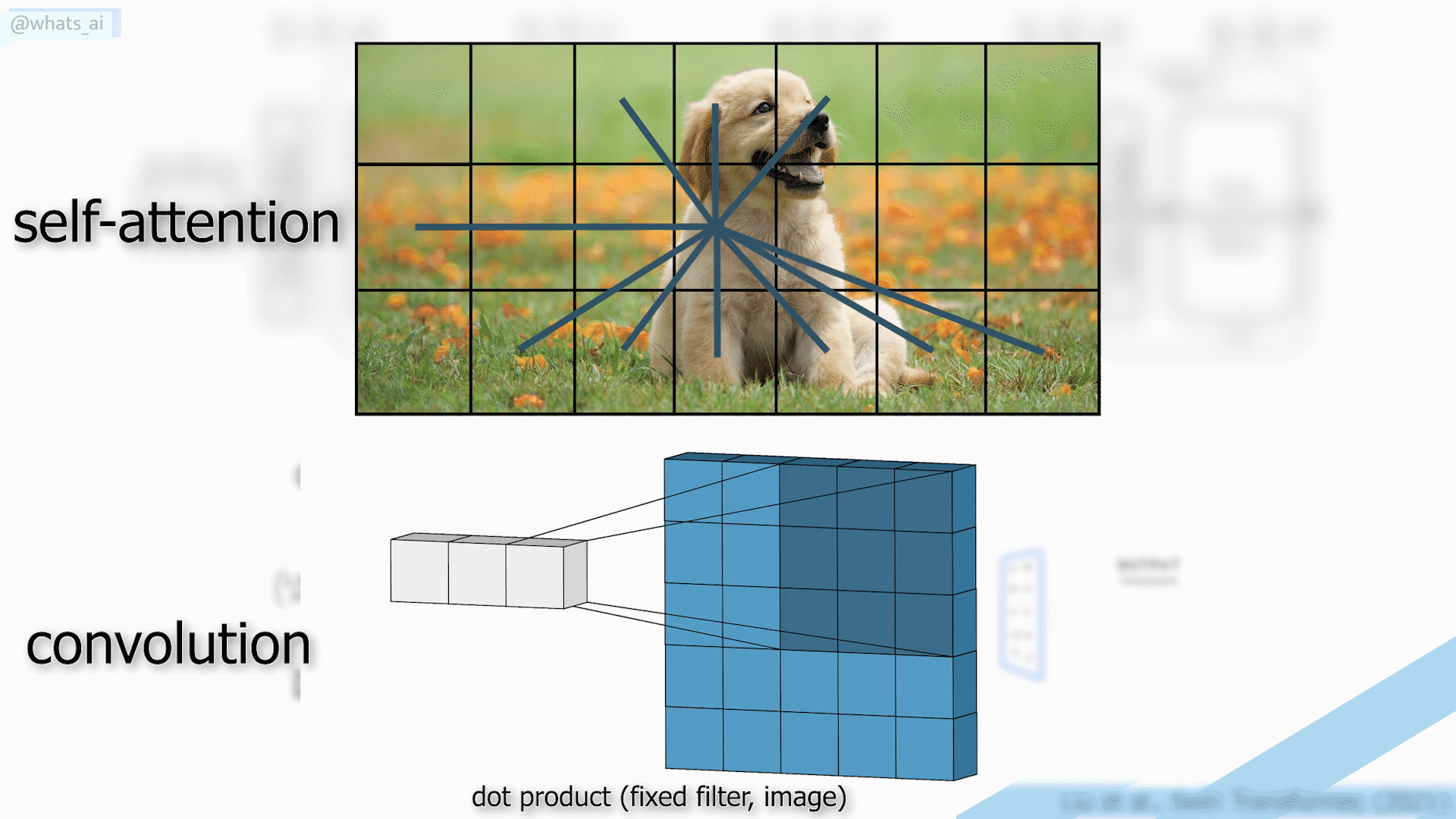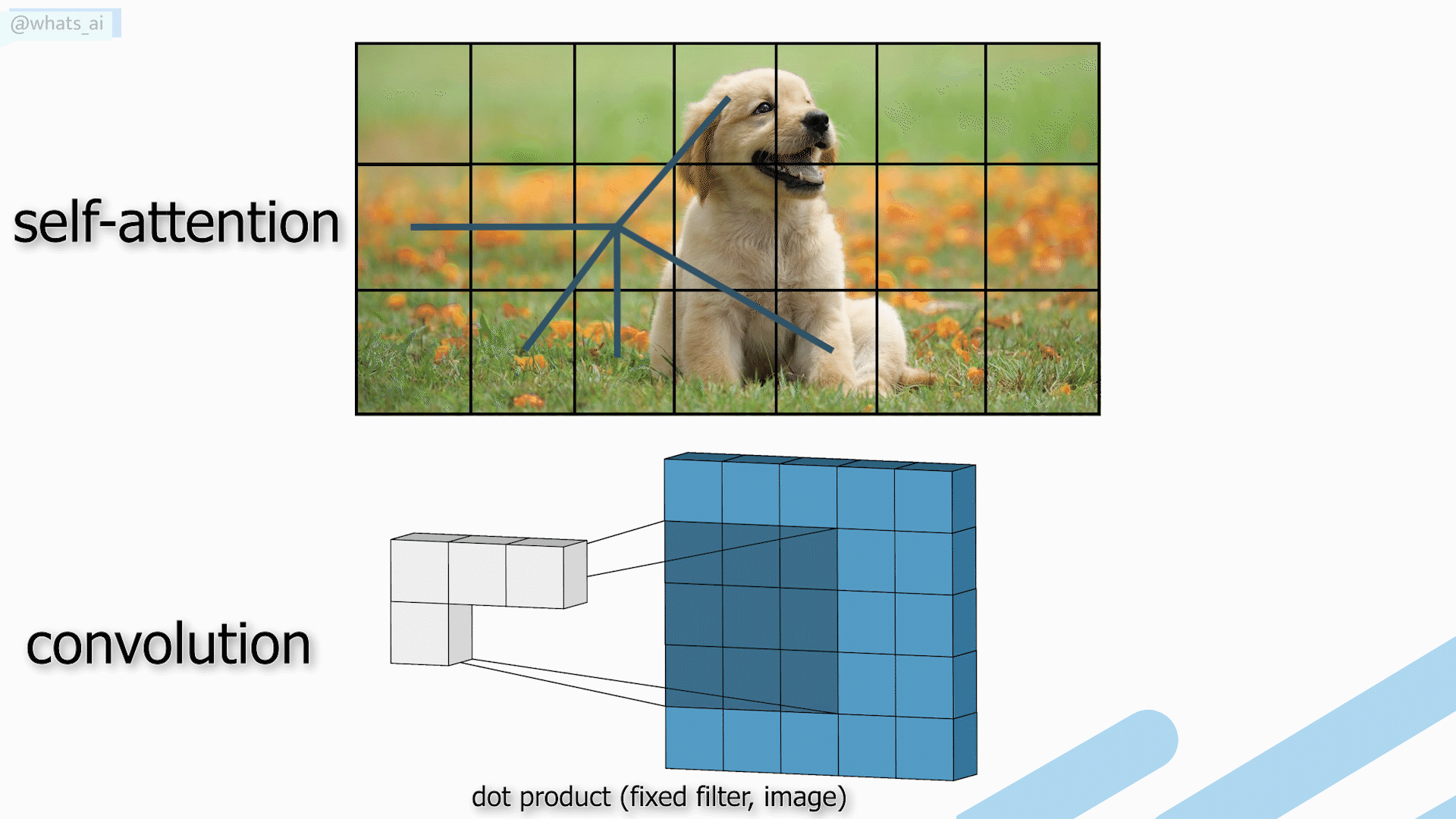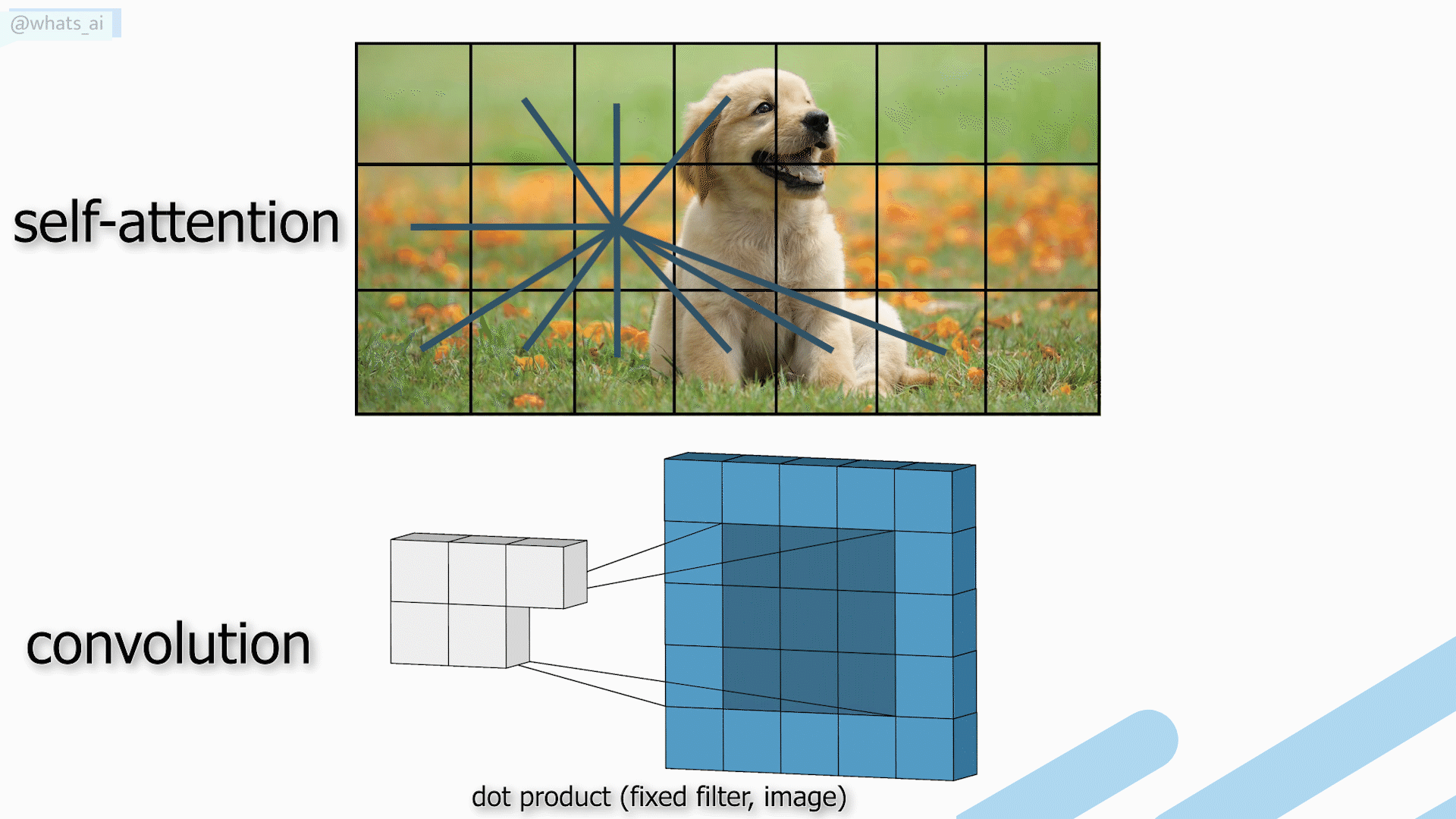
Para lograr eso, generalmente se usa una arquitectura tipo UNet con redes neuronales convolucionales, que expliqué en artículos anteriores, y que te invito a leer si deseas obtener más información. El principal inconveniente es que las CNNs tienen dificultades para adaptarse a conjuntos de datos extremadamente amplios, ya que utilizan los mismos núcleos para todas las imágenes, lo que las hace excelentes para resultados locales y generales, pero menos potentes para resultados globales cuando queremos obtener resultados óptimos para cada imagen individual.
Convoluciones vs autoatención utilizadas en transformadores.
Los Transformers son un tipo de arquitectura muy prometedora gracias a su mecanismo de autoatención que captura interacciones globales entre contextos para cada imagen, pero requieren cálculos muy complejos, no adecuados para imágenes.
Aquí, en lugar de usar CNN o Transformers, crearon una arquitectura similar a UNet con mecanismos de convolución y atención. O, más en concreto, utilizando el Transformer Swin. El Transformer Swin es asombroso ya que tiene la ventaja de las CNNs a la hora de procesar imágenes de mayor tamaño y prepararlas para los mecanismos de atención. Y estos mecanismos de atención crearán conexiones de largo alcance para que el modelo comprenda mucho mejor la imagen general al final y también pueda recrear la imagen mucho mejor. No entraré en detalles sobre el Transformer Swin puesto que ya analicé esta arquitectura hace unos meses, explicando sus diferencias con las CNNs y las arquitecturas de Transformer clásicas utilizadas en el procesamiento del lenguaje natural. Si deseas obtener más información al respecto y entender cómo los investigadores aplicaron Transformers a la Visión Artificial, consulta mi artículo “Towards AI” y vuelve aquí luego para leer la explicación de este modelo de mejora de calidad de imágenes.
SwinIR
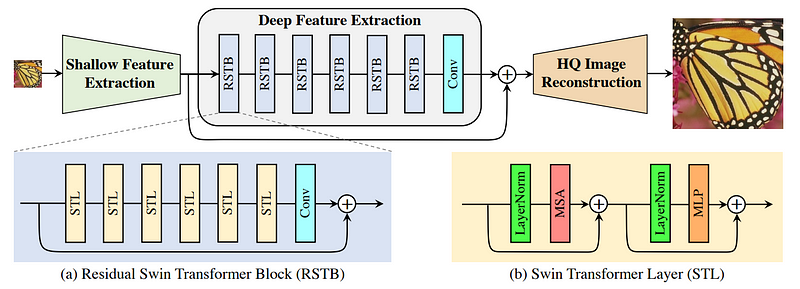
El modelo SwinIR puede realizar muchas tareas con imágenes, incluyendo la mejora de resolución (upsampling). Como he mencionado, usa circunvoluciones, lo que permite imágenes más grandes. En concreto, utiliza una capa convolucional para reducir el tamaño de la imagen, como se observa a continuación.
Arquitectura de SwinIR para la restauración de imágenes. Ilustración de SwinIR [1] .
La imagen reducida se envía al modelo y también pasa directamente al módulo de reconstrucción para obtener información general. Esta representación tendrá el aspecto de múltiples versiones extrañas y borrosas de la imagen, lo que aportará información valiosa al módulo de mejora sobre cómo debería verse la imagen principal. Luego podemos observar las capas del Transformer Swin acopladas con convoluciones. Esto sirve para comprimir aún más la imagen y extraer información precisa sobre el estilo y los detalles, dejando de lado la imagen general. `Por esta razón se vuelve a añadir la imagen convolucionada para obtener la información general que falta con una conexión de salto.
Finalmente, todo esto se envía a un módulo de reconstrucción llamado Subpíxel, que utiliza tanto las características generales más grandes como las características detalladas más pequeñas que acabamos de crear para reconstruir una imagen de mayor definición. Puedes imaginar esto como una red neuronal convolucional pero al revés, o simplemente como un decodificador, que recoge las características condensadas originales y reconstruye una imagen más grande a partir de ellas. De nuevo, si deseas obtener más información sobre las CNNs y los decodificadores, consulta algunos de los artículos que publiqué sobre ellos.
Por lo tanto, se envía la imagen a una CNN, donde se crea una representación que será utilizada más tarde, y a la arquitectura del Transformer Swin, para comprimir aún más la información y analizar las características más importantes cuya resolución se pretende mejorar. Despu´és se integran todos los datos y se reconstruye la versión de alta definición mediante un decodificador.
¡Y voilá!
Solo necesitas un volumen adecuado de datos para obtener resultados tan increíbles como este (¡míralo en este video !).
Por supuesto, como en cualquier otra cosa, existen algunas limitaciones… En este caso, probablemente debido a la capa convolucional inicial, este método no funciona bien con imágenes muy pequeñas (de menos de 200 píxeles de ancho) y puede que aparezcan cosas raras y resultados extraños…
Versión mejorada de una imagen de 175 x 183 con SwinIR.
Parece que también se puede usar esta tecnología para eliminar las arrugas… Fuera de eso, los resultados son bastante locos, pero tras haber jugado mucho con él en los últimos días, creo que la mejora de X4 es increíble.
¡Tú también puedes jugar con él! El repositorio de GitHub está disponible para todo el mundo y en él se encuentran modelos preentrenados e incluso una demo con la que puedes probarlo sin necesidad de introducir ningún código. Por supuesto, esto ha sido solo una descripción general de este increíble nuevo modelo, así que te invito encarecidamente a leer el informe completo para una comprensión técnica más profunda. Todos los enlaces están en las referencias a continuación. ¡Cuéntame qué te ha parecido, espero que hayas disfrutado la lectura!
¡Gracias una vez más a Weights & Biases por patrocinar el video y el artículo y a todos los que todavía están leyendo!
¡Nos vemos la próxima semana con otro artículo interesante!
Si te gusta mi trabajo y quieres estar al día con la IA, sígueme en mis otras cuentas de redes sociales (LinkedIn, Twitter) y suscríbete a mi boletín semanal de IA.
Para apoyarme:
La mejor manera de apoyarme es siendo miembro de este sitio web o suscribiéndote a mi canal en YouTube si te gusta el formato video.
¿Quieres aprender sobre IA o mejorar tus conocimientos? Lee esto !
Referencias
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L. y Timofte, R., 2021. SwinIR: restauración de imágenes con un transformer swin. Actas de la Conferencia Internacional IEEE/CVF sobre Visión Artificial (págs. 1833–1844).
Translation into Spanish of an interesting article by Peter Warden, CTO of Jetpac Inc, author of "The Public Data Handbook" and "The Big Data Glossary for O’Reilly", builder of "Open Heat Map", the "Data Science Toolkit", and other interesting open source projects.
Translation into Spanish of an interesting article by Stephanie Seneff, is a senior research scientist at the Computer Science and Artificial Intelligence Laboratory (CSAIL) at the Massachusetts Institute of Technology (MIT). Working primarily in the Systems of Spoken Language group, his...
Translation into Spanish of an interesting article by Tapajyoti Bose, experienced web developer specializing in REACT, who creates "highly performant responsive web apps, which are a charm to use".